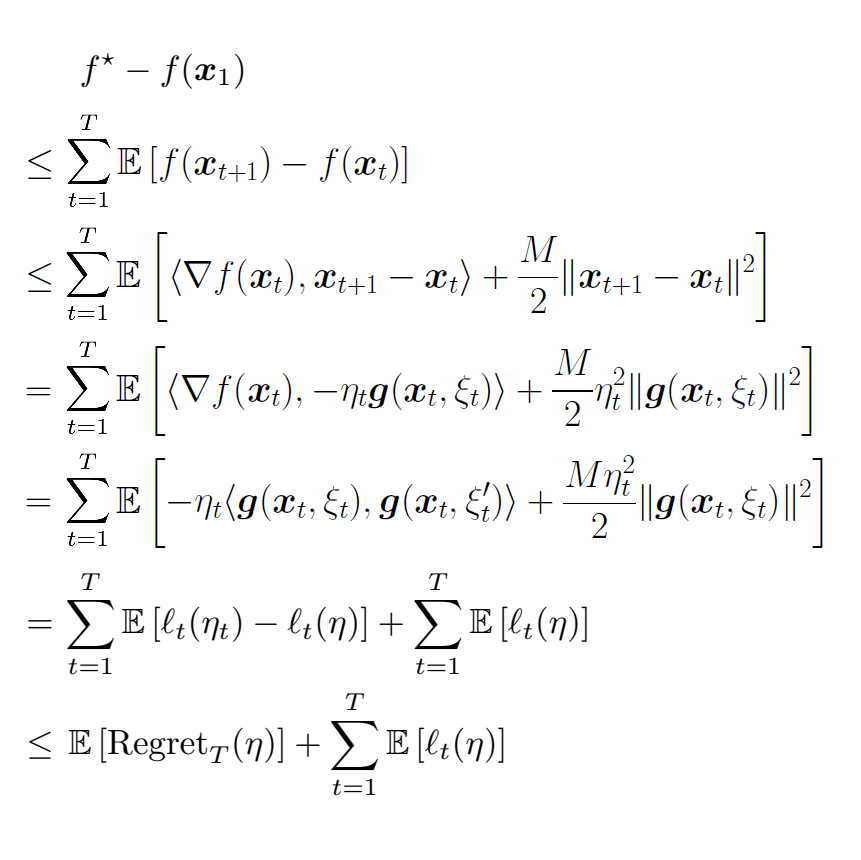
Robustness to Unbounded Smoothness of Generalized SignSGD
Michael Crawshaw, Mingrui Liu, Francesco Orabona, Wei Zhang, Zhenxun Zhuang (alphabetical order).
Conference on Neural Information Processing Systems, November, 2022.

Hello! I joined Meta as a Research Scientist after obtaining my Ph.D. degree in the Department of Computer Science at Boston University. Being a member of the Optimization and Machine Learning Lab, I was advised by Professor Francesco Orabona. My research focuses on designing algorithms for non-convex optimization problems, with special interests on Stochastic Gradient Descent (SGD) and its many variants. Apart from proving theoretical guarantees for these algorithms, I am also very passionate about investigating their empirical performance in fields like deep learning.
Ph.D. in Computer Science
Dissertation: Adaptive Strategies in Non-convex Optimization
Adviser: Francesco Orabona
Ph.D. in Computer Science
Adviser: Francesco Orabona
B.Eng. in Electronic Information Engineering
Thesis: Prediction & Transform Combined Intra Coding in HEVC
Adviser: Feng Wu


Zhenxun Zhuang, Yunlong Wang, Kezi Yu, and Songtao Lu.
Proceedings of the 45th International Conference on Acoustics, Speech, and Signal Processing, May, 2020
Zhenxun Zhuang, Kezi Yu, Songtao Lu, Lucas Glass, Yunlong Wang.
NeurIPS Workshop on Meta-Learning (MetaLearn 2019), Dec, 2019
PyTorch implementation of the paper: Robustness to Unbounded Smoothness of Generalized SignSGD.
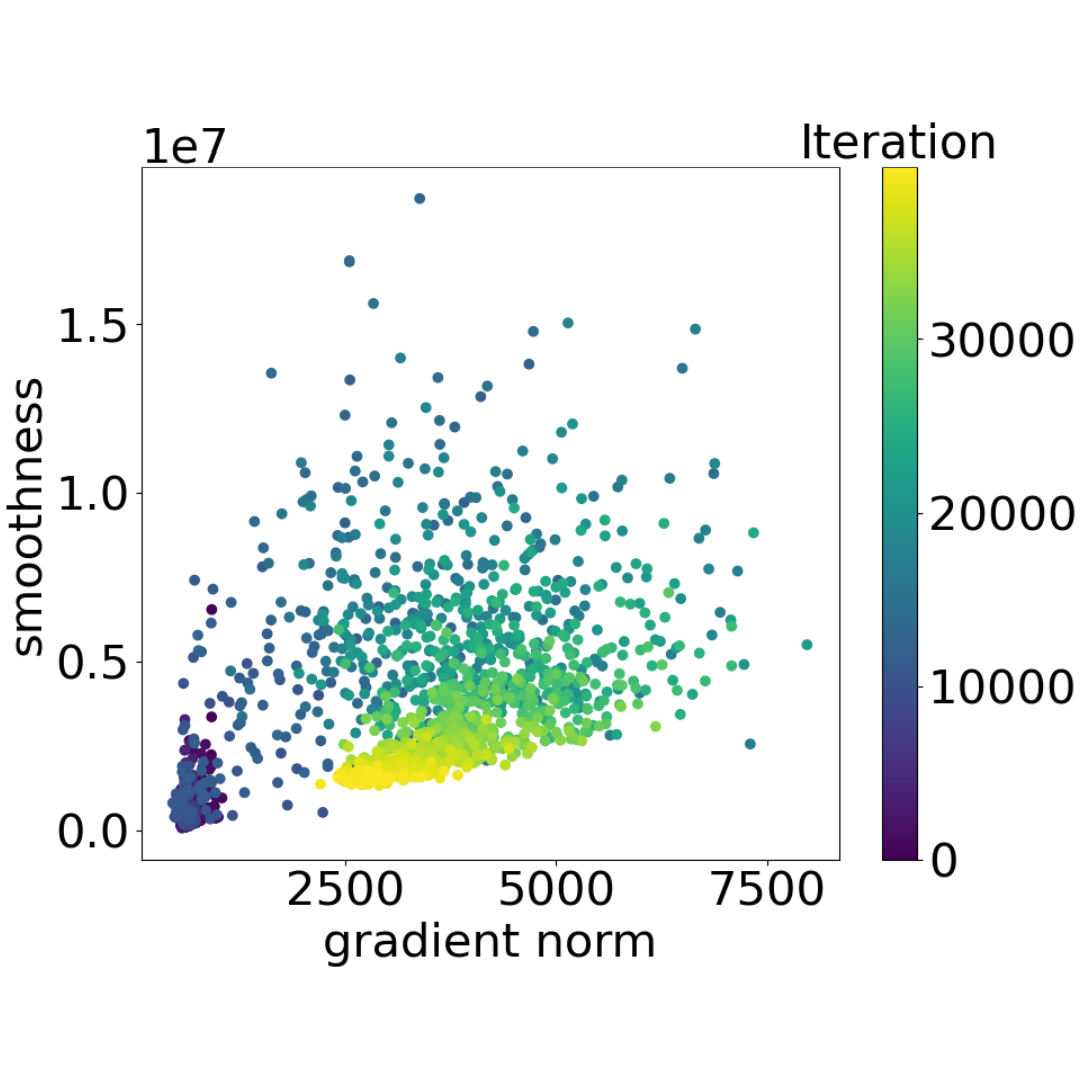
Traditional analyses in non-convex optimization typically rely on the smoothness assumption, namely requiring the gradients to be Lipschitz. However, recent evidence shows that this smoothness condition does not capture the properties of some deep learning objective functions, including the ones involving Recurrent Neural Networks and LSTMs. Instead, they satisfy a much more relaxed condition, with potentially unbounded smoothness. Under this relaxed assumption, it has been theoretically and empirically shown that the gradient-clipped SGD has an advantage over the vanilla one. In this paper, we show that clipping is not indispensable for Adam-type algorithms in tackling such scenarios: we theoretically prove that a generalized SignSGD algorithm can obtain similar convergence rates as SGD with clipping but does not need explicit clipping at all. This family of algorithms on one end recovers SignSGD and on the other end closely resembles the popular Adam algorithm. Our analysis underlines the critical role that momentum plays in analyzing SignSGD-type and Adam-type algorithms: it not only reduces the effects of noise, thus removing the need for large mini-batch in previous analyses of SignSGD-type algorithms, but it also substantially reduces the effects of unbounded smoothness and gradient norms. We also compare these algorithms with popular optimizers on a set of deep learning tasks, observing that we can match the performance of Adam while beating the others.
Check my project.PyTorch implementation of the paper: A Communication-Efficient Distributed Gradient Clipping Algorithm for Training Deep Neural Networks.
In distributed training of deep neural networks, people usually run Stochastic Gradient Descent (SGD) or its variants on each machine and communicate with other machines periodically. However, SGD might converge slowly in training some deep neural networks (e.g., RNN, LSTM) because of the exploding gradient issue. Gradient clipping is usually employed to address this issue in the single machine setting, but exploring this technique in the distributed setting is still in its infancy: it remains mysterious whether the gradient clipping scheme can take advantage of multiple machines to enjoy parallel speedup. The main technical difficulty lies in dealing with nonconvex loss function, non-Lipschitz continuous gradient, and skipping communication rounds simultaneously. In this paper, we explore a relaxed-smoothness assumption of the loss landscape which LSTM was shown to satisfy in previous works, and design a communication-efficient gradient clipping algorithm. This algorithm can be run on multiple machines, where each machine employs a gradient clipping scheme and communicate with other machines after multiple steps of gradient-based updates. Our algorithm is proved to have 1/(N*\epsilon^4)) iteration complexity and 1/\epsilon^3 communication complexity for finding an \epsilon-stationary point in the homogeneous data setting, where N is the number of machines. This indicates that our algorithm enjoys linear speedup and reduced communication rounds. Our proof relies on novel analysis techniques of estimating truncated random variables, which we believe are of independent interest. Our experiments on several benchmark datasets and various scenarios demonstrate that our algorithm indeed exhibits fast convergence speed in practice and thus validates our theory.
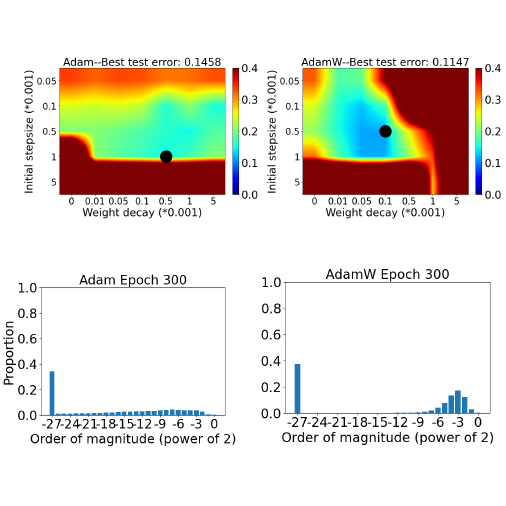
Check my project.PyTorch implementation of the paper: Understanding AdamW through Proximal Methods and Scale-freeness.
Adam has been widely adopted for training deep neural networks due to less hyperparameter tuning and remarkable performance. To improve generalization, Adam is typically used in tandem with a squared l2 regularizer (referred to as Adam-l2). However, even better performance can be obtained with AdamW, which decouples the gradient of the regularizer from the update rule of Adam-l2. Yet, we are still lacking a complete explanation of the advantages of AdamW. In this paper, we tackle this question from both an optimization and an empirical point of view. First, we show how to re-interpret AdamW as an approximation of a proximal gradient method, which takes advantage of the closed-form proximal mapping of the regularizer instead of only utilizing its gradient information as in Adam-l2. Next, we consider the property of "scale-freeness" enjoyed by AdamW and by its proximal counterpart: their updates are invariant to component-wise rescaling of the gradients. We provide empirical evidence across a wide range of deep learning experiments showing a correlation between the problems in which AdamW exhibits an advantage over Adam-l2 and the degree to which we expect the gradients of the network to exhibit multiple scales, thus motivating the hypothesis that the advantage of AdamW could be due to the scale-free updates.
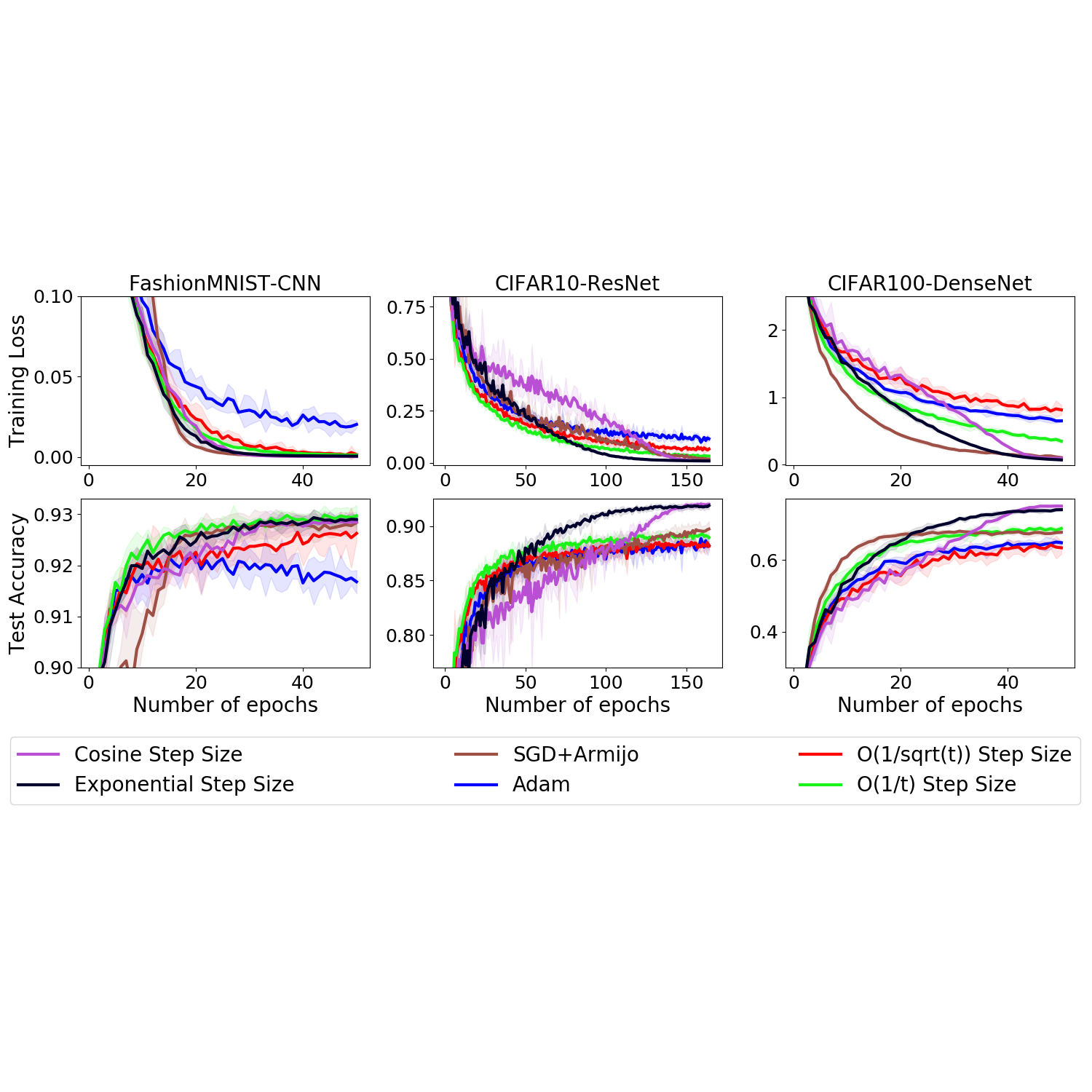
Check my project.PyTorch implementation of the paper: A Second look at Exponential and Cosine Step Sizes: Simplicity, Convergence, and Performance.
Stochastic Gradient Descent (SGD) is a popular tool in training large-scale machine learning models. Its performance, however, is highly variable, depending crucially on the choice of the step sizes. Accordingly, a variety of strategies for tuning the step sizes have been proposed. Yet, most of them lack a theoretical guarantee, whereas those backed by theories often do not shine in practice. In this paper, we study two heuristic step size schedules whose power has been repeatedly confirmed in practice: the exponential and the cosine step sizes. We conduct a fair and comprehensive empirical evaluation of real-world datasets with deep learning architectures. Results show that, even if only requiring at most two hyperparameters to tune, they best or match the performance of various finely-tuned state-of-the-art strategies.
Check my project.PyTorch implementation of SGDOL from the paper: Surrogate Losses for Online Learning of Stepsizes in Stochastic Non-Convex Optimization.
Non-convex optimization has attracted lots of attention in recent years, and many algorithms have been developed to tackle this problem. Many of these algorithms are based on the Stochastic Gradient Descent (SGD) proposed by Robbins & Monro over 60 years ago. SGD is intuitive, efficient, and easy to implement. However, it requires a hand-picked parameter, the stepsize, for (fast) convergence, which is notoriously tedious and time-consuming to tune. Over the last several years, a plethora of adaptive gradient-based algorithms have emerged to ameliorate this problem. They have proved efficient in reducing the labor of tuning in practice, but many of them lack theoretic guarantees even in the convex setting. In this project, I implemented the SGDOL algorithm with self-tuned stepsizes that guarantees convergence rates that are automatically adaptive to the level of noise.
Check my project.An interactive web-based data visualization system using D3.js for analyzing the Times Higher Education World University Ranking.
More or less, we all like rankings, and we all make rankings. One of the most popular subject for ranking is reputation of universities. Although people have been arguing over their credibility and validity for years, university rankings are still considered as an important factor during the application phase. However, there have already been tens of various national and international ranking systems avaiable right now, and all of them somehow disagree with each other. This is because different ranking systems emphasize different things and use different ranking mechanisms. Therefore, before referencing a rank, we should be aware of which factors are included and how they affect the results. In this project, I do not intend to develop a novel ranking system; instead, I try to analyse the Times Higher Education World University Rankings to discover some interesting patterns.
Check my project.More to come soon...